
Se você cria pipelines de IA que leem PDFs, já conhece o dilema: alguns parsers são rápidos, mas perdem estrutura; outros preservam qualidade, porém aumentam a latência.
O LiteParse é um parser de código aberto do ecossistema LlamaIndex focado em velocidade + estrutura útil para fluxos locais.
Diferencial do LiteParse para RAG
Em RAG, qualidade de extração não é apenas extrair texto. É preservar sinais que ajudam na recuperação e no raciocínio:
- Posição relativa dos blocos de texto;
- Alinhamento de colunas;
- Espaçamento de tabelas;
- Limites de página.
O LiteParse preserva o layout original do documento ao projetar o texto em uma representação espacial (em vez de tentar reescrever tudo de forma agressiva para markdown).
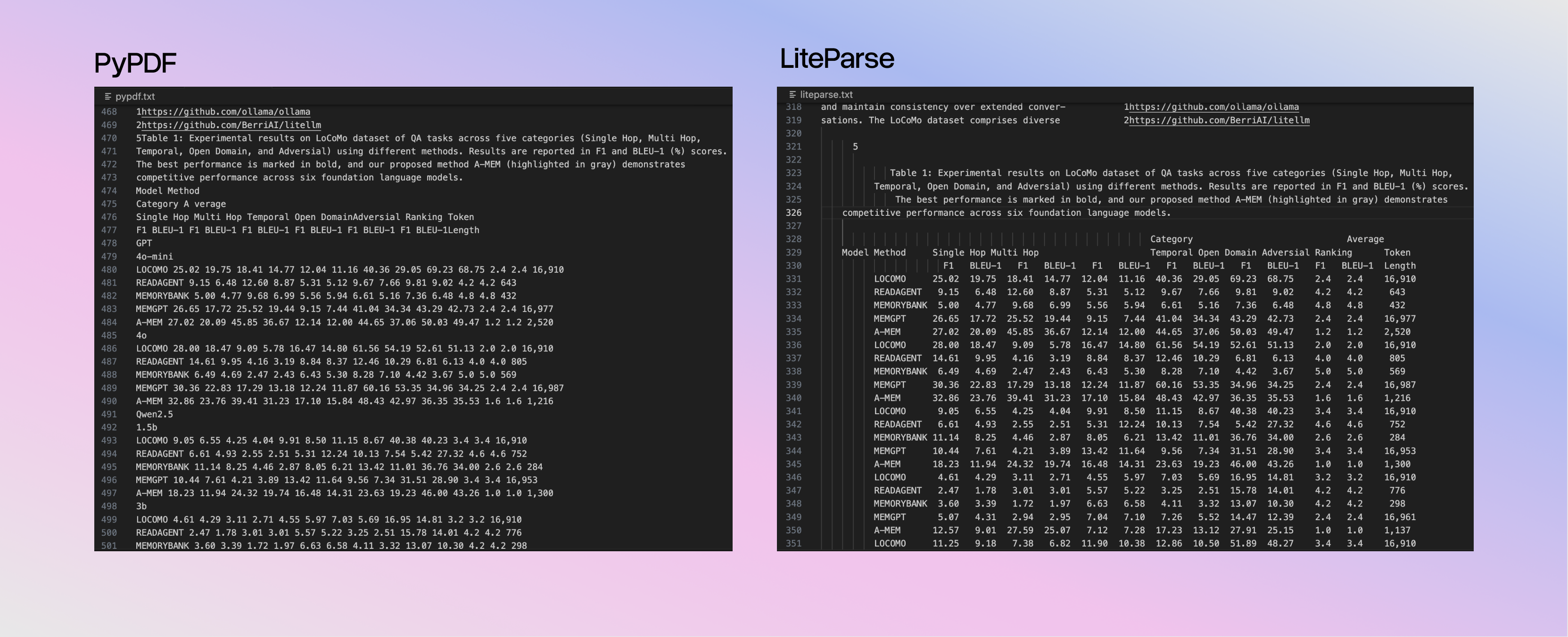
Isso importa porque LLMs modernos leem muito bem esses padrões de layout. Manter essa estrutura melhora:
- Fidelidade dos chunks na indexação;
- Recall na recuperação;
- Respostas mais fundamentadas (menos alucinação por contexto quebrado).
Exemplo: parsing de PDF em Python
Instale o pacote:
|
|
Execute o código:
|
|
Esse resultado mantém pistas de espaço/alinhamento importantes do PDF original.
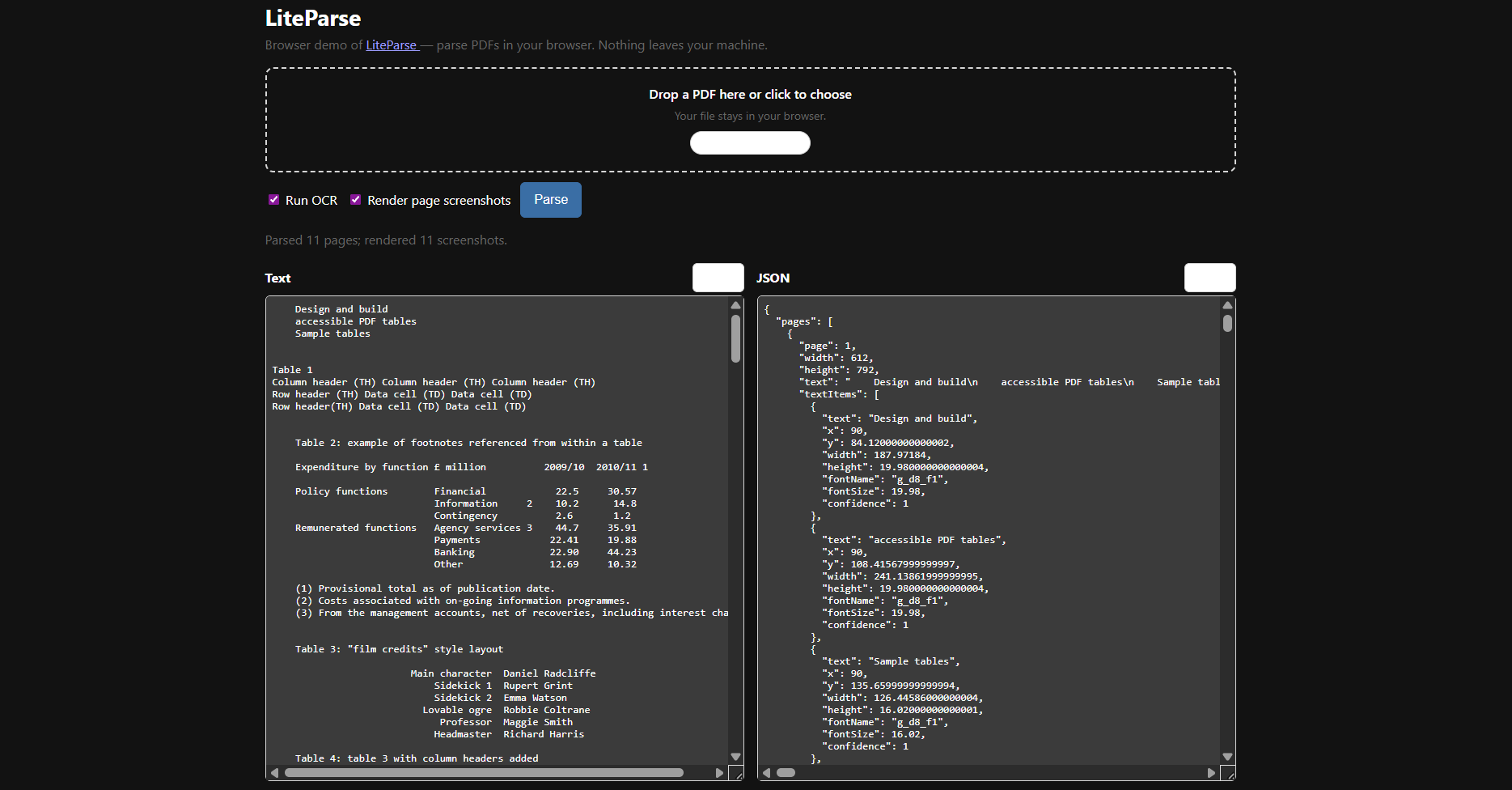
Exemplo: teste online
Você pode testar o LiteParse de maneira 100% gratuita online em qualquer arquivo PDF no link: https://simonw.github.io/liteparse/.
OCR e Documentos Complexos
O LiteParse suporta OCR e pode ser usado com OCR padrão ou servidores OCR externos para casos mais complexos.
Para PDFs escaneados, você mantém um único fluxo em Python e ainda recebe saída com preservação de layout.