Se você já precisou manter um EFS separado só para dar acesso no estilo de sistema de arquivos a dados que já estavam no S3, sabe o quão frustrante é essa duplicação. Você paga duas vezes, sincroniza manualmente e ainda lida com problemas de consistência eventual.
A AWS acabou de lançar uma solução para isso: S3 Files.
O Que É o S3 Files?
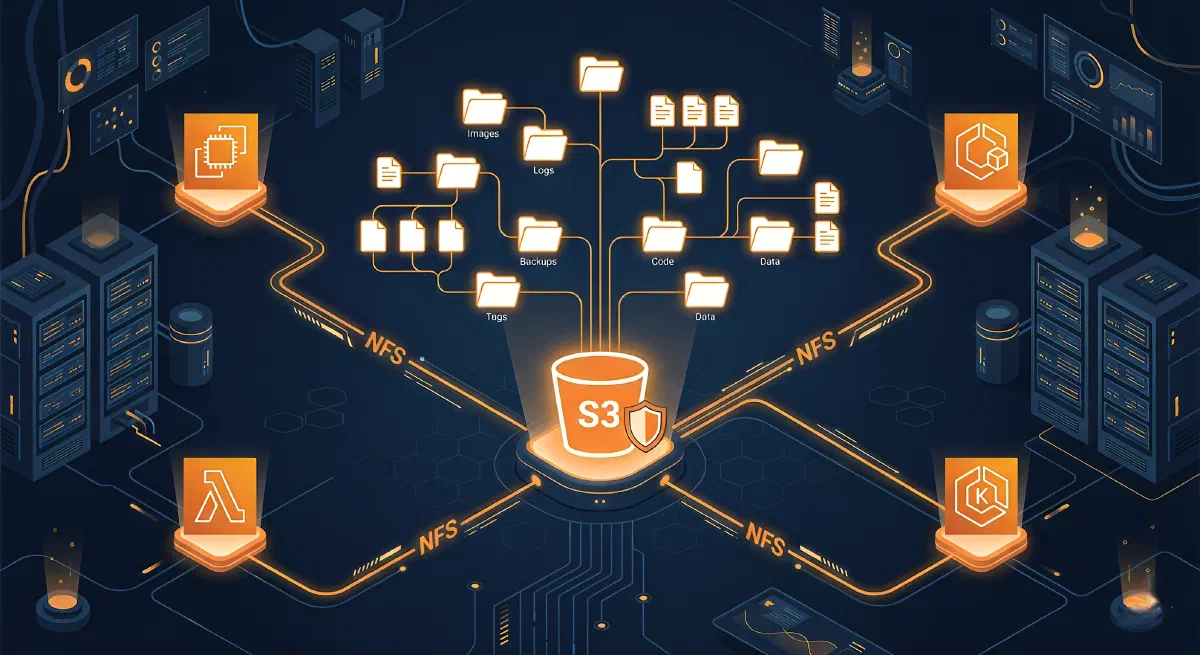
S3 Files é um novo serviço da AWS que torna buckets S3 acessíveis como sistemas de arquivos nativos usando NFS v4.1+. Em vez de tratar seu bucket como um armazenamento chave-valor acessado via URLs s3://, você o monta como um diretório comum e usa operações POSIX normais: ls, cp, cat, echo >, qualquer coisa.
Por baixo dos panos, ele roda na infraestrutura do Amazon EFS e entrega latências de ~1ms para dados ativos. Arquivos com muitas leituras sequenciais são servidos diretamente do S3 para maximizar o throughput, com leituras por byte-range para minimizar custos de transferência.
|
|
Como Funciona o Cache (e Por Que Isso Importa para o Custo)
Essa é a parte que impacta diretamente sua fatura. O S3 Files usa uma estratégia de tiering inteligente:
- Arquivos acessados com frequência e de forma aleatória → cacheados no armazenamento de alta performance do file system (~1ms)
- Arquivos lidos sequencialmente em grandes blocos → servidos diretamente do S3 (mais barato, maior throughput)
- Leituras por byte-range reduzem transferência de dados desnecessária
O resultado: você não está colocando tudo cegamente em storage com preço de EFS. O sistema descobre o que precisa ser rápido e o que pode ficar barato no S3.
Configurando o S3 Files
Pelo Console
- Vá em S3 → File systems → Create file system
- Digite o nome do seu bucket e confirme
- Anote os Mount Target IDs na aba Mount targets
- Acesse sua instância EC2 via SSH e monte:
|
|
Certifique-se de ter o pacote
amazon-efs-utilsmais recente instalado. Ele já vem pré-instalado nas AMIs da AWS.
Pela CLI
|
|
Permissões IAM
O S3 Files usa IAM para controlar o acesso tanto no nível do file system quanto no nível dos objetos. Você precisará de políticas que permitam as ações s3files:* e s3:GetObject/s3:PutObject para as roles dos seus recursos de computação.
Acesso Compartilhado Sem Duplicação de Dados
Um dos maiores ganhos aqui é o acesso multi-compute com uma única cópia dos dados. Você pode montar o mesmo file system em:
- Instâncias EC2
- Tasks do ECS
- Pods do EKS
- Funções Lambda
Antes do S3 Files, um workaround comum era copiar os dados para o EFS para que múltiplos serviços pudessem lê-los como arquivos, o que significava manter duas cópias do mesmo dataset e pagar por ambas. Agora você monta o mesmo file system respaldado pelo S3 em todos os lugares.
| Cenário | Antes | Com S3 Files |
|---|---|---|
| Dados de treino compartilhados entre pods EKS | Copiar para EFS + job de sync com S3 | Mount único, fonte única da verdade |
| Lambda lendo arquivos de configuração | Código customizado com SDK S3 por função | I/O de arquivos padrão via mount |
| EC2 + ECS compartilhando o mesmo dataset | Sync manual ou acesso via objeto S3 | Mount NFS compartilhado, consistência close-to-open |
Comportamento de Sincronização
Arquivos gravados pelo file system aparecem no S3 em poucos minutos. Mudanças feitas diretamente no bucket S3 (via CLI ou SDK) refletem no file system em poucos segundos, embora ocasionalmente possa levar até um minuto.
Essa sincronização bidirecional significa que você pode misturar padrões de acesso, alguns serviços usando o mount, outros usando a API S3, sem precisar manter um pipeline de sync separado.
O Que Você Paga
O pricing do S3 Files tem três componentes:
- Dados armazenados no S3 file system
- Leituras de arquivos pequenos e todas as operações de escrita pelo file system
- Requisições à API do S3 durante a sincronização entre o file system e o bucket
Você não paga pelo armazenamento S3 subjacente duas vezes, os objetos ficam no S3 e você é cobrado nas tarifas do S3 pelo armazenamento. A camada do file system adiciona um custo sobre isso pela infraestrutura NFS e de cache, mas você evita o custo total do EFS para dados que não precisam de cache de alta performance permanente.
Onde o S3 Files Brilha
- Sistemas de IA agêntica que usam bibliotecas Python baseadas em arquivos e ferramentas CLI que esperam um filesystem real
- Pipelines de treino de ML onde múltiplos nós precisam de acesso de leitura compartilhado a datasets
- Aplicações migrando de NFS on-prem que não estão prontas para reescrever todo o acesso a storage para chamadas ao S3 SDK
- Padrões Lambda + I/O de arquivos sem a complexidade do S3
Quando Continuar com FSx ou EFS
O S3 Files não é a ferramenta certa para tudo:
- Clusters HPC/GPU com workloads otimizados para Lustre → use FSx for Lustre
- Migrações NAS de ambientes Windows ou NetApp → use FSx for Windows / FSx for NetApp ONTAP
- Latência consistente abaixo de 1ms em escala sem S3 como backing store → use EFS diretamente
Monitoramento
Métricas do CloudWatch e logs do CloudTrail estão disponíveis para todas as operações do S3 Files. Configure alertas de latência e throughput da mesma forma que faria para o EFS, a superfície de métricas é familiar.
Resumo
O S3 Files elimina um dos motivos mais comuns para se manter armazenamento redundante: dar acesso no estilo de sistema de arquivos a dados que já estavam no S3. O modelo de cache inteligente significa que você não está pagando tarifas de EFS por tudo, apenas pelo que realmente se beneficia de acesso com baixa latência. Está disponível em todas as regiões comerciais da AWS hoje.
Se você tem workloads que leem dados do S3 por wrappers do SDK apenas para simular acesso a arquivos, vale a pena avaliar. A configuração é simples e o modelo de custo é mais previsível do que manter um volume EFS paralelo.