Everyone knows that ensuring and validating data quality is still an extremely laborious task in most cases, and that’s the problem Great Expectations aims to solve. Today we’ll talk about this incredible data quality tool.
Introduction
The “Great Expectations” library: built in Python, is a powerful tool for data validation. It allows you to define expectations about what your data should look like and then verify that those expectations are met. This serves to ensure data quality before proceeding with analysis or modeling.
The “Great Expectations” library is built on top of Pandas, which I believe is today the most widely used tool in the data space, meaning you can easily integrate it into your existing pipelines.
To get started, let’s install the “Great Expectations” library. This can be done using the following command:
|
|
Using Great Expectations with Pandas DataFrames
The Great Expectations library is enormous: with integrations for most existing tools and databases, but to keep things simple in this article we’ll use it together with Pandas.
First let’s load our data. I’ll use the iris dataset, as I believe most people have heard about it:
|
|
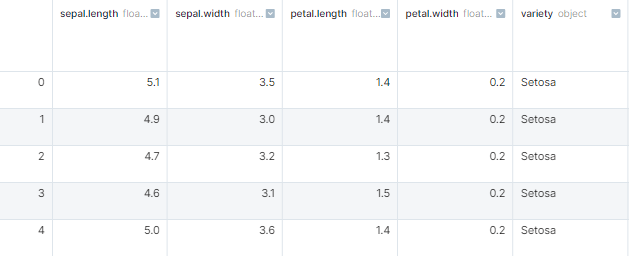
Now to start defining our expectations about this data, let’s convert this Pandas dataframe into a Great Expectations dataframe:
|
|
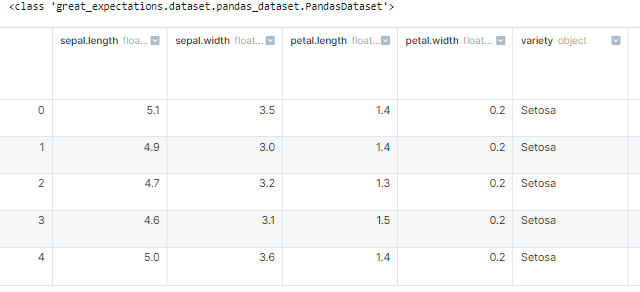
Note: A Great Expectations dataframe is just an abstraction that uses a Pandas dataframe, so we can use this dataframe as if it were a regular Pandas dataframe.
Now let’s create some expectations.
|
|
There are hundreds of distinct expectations, I recommend taking a look at the documentation at https://greatexpectations.io/expectations/.
The definition of each expectation returns an object called “ExpectationValidationResult” that contains all data related to the result of that expectation. For example, this is the result of expectation 2:
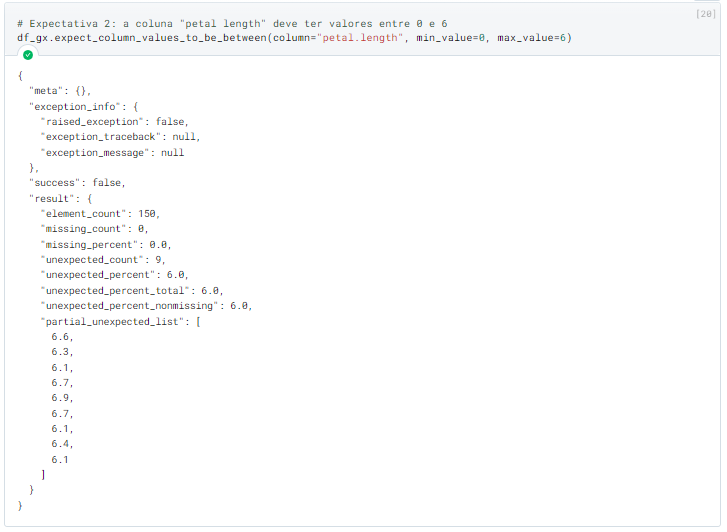
As we can see: the result indicates that the expectation failed (the “success” field shows “false”), and furthermore: it also brings us some error details, such as the number of incorrect values, what percentage these values represent of the total, a sample of these values, and various other metrics that will depend on which expectation was used.
Let’s now adjust our expectation so it doesn’t fail:
|
|

Now, our expectation is being met. Note that even with a positive result, we are still shown an example of the values that did not meet the main criteria of the expectation.
If you don’t want to validate all your expectations one by one, don’t worry — all expectations are automatically stored in the dataframe, and you can view the result of all your expectations as follows:
|
|

The “.validate” method will return the result of all your expectations at once, as well as bring all the data related to the result of each one.
Conclusion
The “Great Expectations” library is a powerful tool for data validation in Python. In addition to being extremely simple to use, with its ability to define and validate clear expectations about data, the library allows you to maintain data quality over time and avoid future errors.
Moreover, with its high level of customization and integration, it fits perfectly into many existing data pipelines and can be a valuable addition. Therefore, if you work with Python, I strongly recommend taking a deeper look at its capabilities.