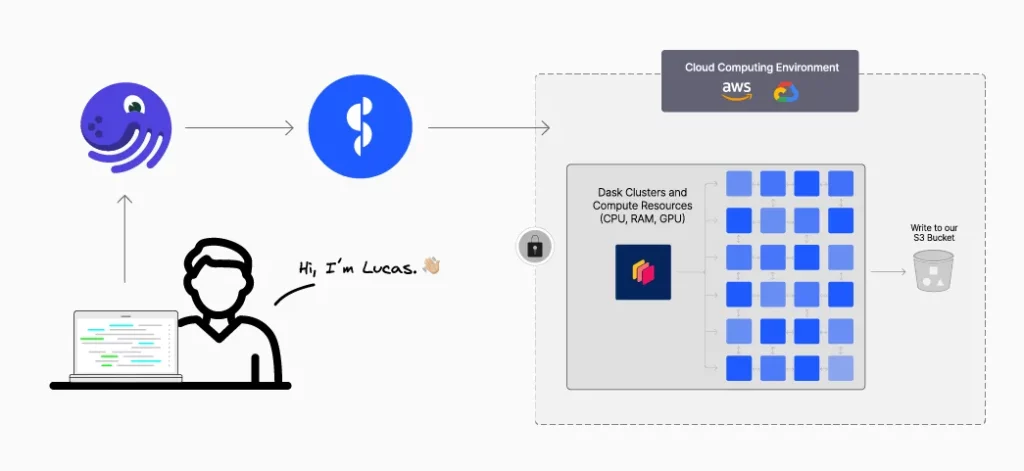
Neste artigo irei mostrar uma integração simples entre o Dagster e o Dask+Coiled. Discutiremos como isso tornou um problema comum, processar um grande conjunto de arquivos mensalmente, realmente uma tarefa muito fácil.
O Usuário e o Problema
Olá  , me chamo Lucas, sou o líder do time de ciência e engenharia de dados na OnlineApp, uma empresa B2B que atende o mercado brasileiro.
, me chamo Lucas, sou o líder do time de ciência e engenharia de dados na OnlineApp, uma empresa B2B que atende o mercado brasileiro.
Todo mês, o governo brasileiro publica um grande conjunto de arquivos CSV com informações sobre empresas brasileiras, que usamos para entender melhor o nosso mercado. Temos muitos serviços internos que desejam ler esses dados, mas antes que isso seja possível, precisamos pré-processar um pouco eles:
- Filtrar algumas linhas e colunas que não nos interessam;
- Limpar alguns valores em várias colunas;
- Realizar junções com outros conjuntos de dados internos que temos;
- Converter para Parquet e armazenar em nosso próprio armazenamento em cloud;
Temos muitos outros serviços em nossa empresa que então dependem desses dados.
Arquitetura
Para processos regulares como esses, executados de forma agendada, geralmente utilizamos o Dagster. Gostamos de utilizar o Dagster porque é fácil de usar e parece natural (intuitivo). Ele é executado em uma VM na nuvem, o que nos proporciona acesso rápido a outros dados na nuvem (como esses arquivos CSV).
Normalmente, usaríamos o Pandas para esse tipo de processo, mas esse conjunto de arquivos é muito grande para caber na memória (cerca de ≅150 milhões de linhas com várias colunas), então mudamos para o Dask. Infelizmente, o conjunto de dados também é grande demais para a nossa VM que executa o Dagster, então decidimos utilizar o Coiled para solicitar um cluster de máquinas maiores, cada uma com uma quantidade razoável de memória.
Em princípio, queríamos fazer algo assim:
import coiled
import dask.dataframe as dd
from dagster import op
@op
def run_operation(context):
'''Processa todos os arquivos CSV e salva o resultado como Parquet.'''
cluster = coiled.Cluster(
region="sa-east-1",
memory="64 GiB",
n_workers=100,
... # outras opções de configuração que você precisa
)
client = cluster.get_client()
df = dd.read_csv("...")
... # código personalizado específico para o nosso problema
df_result.to_parquet("...")
Isso funcionaria, mas queríamos tornar isso mais natural integrando-o com o Dagster. E estamos animados para compartilhar o que fizemos.
Integração Dagster + Coiled
O Dagster possui o conceito de Recurso (Resource). Recursos geralmente modelam componentes externos com os quais Ativos (Assets) e Operações (Ops, abreviação de “Operações”, como no exemplo acima) interagem. Por exemplo, um recurso pode ser uma conexão com um data warehouse como o Snowflake ou um serviço como uma API REST.
Para tornar o recurso do Dask+Coiled mais reutilizável e também aproveitar toda a funcionalidade adicional que o Dagster oferece ao trabalhar com recursos (mais sobre isso posteriormente), transformamos nosso cluster Coiled em um recurso do Dagster. Isso é tão fácil de fazer quanto:
from contextlib import contextmanager
from dagster import resource
import coiled
@resource(
config_schema={
"n_workers": int,
"worker_memory": str
}
)
@contextmanager
def dask_coiled_cluster_resource(context):
'''Yields a Dask cluster client.'''
with coiled.Cluster(
name=f"dagster-dask-cluster-{context.run_id}",
n_workers=context.resource_config["n_workers"],
worker_memory=context.resource_config["worker_memory"],
region="sa-east-1", # use sua região preferida
compute_purchase_option="spot_with_fallback", # economiza dinheiro com spot
) as cluster:
with cluster.get_client() as client:
context.log.info(
f"Cluster criado, dashboard link: {client.dashboard_link}"
)
yield client
Para usar este recurso, nós o adicionamos à definição do nosso Job:
from dagster import job
@job(
resource_defs={
"dask_cluster": dask_coiled_cluster_resource,
},
config={
"resources": {
"dask_cluster": {
# define os valores padrão, mas você pode alterá-los
# na UI do Dagster ou posteriormente no código
"config": {
"n_workers": 5,
"worker_memory": "64GiB"
},
},
},
}
)
def my_job():
'''Minha definição de DAGs do Job.'''
...
result = my_op()
...
E por fim, nas operações que necessitam de um cluster Dask para rodar computações, informamos essas dependências da seguinte forma:
from dagster import op
@op(
# especifique a chave de recurso que você deseja usar nesta operação
required_resource_keys={"dask_cluster"}
)
def my_op(context):
'''Run my computation with a Dask cluster.'''
# cada computação dentro desta operação será executado com o cluster Dask
...
# também podemos acessar e usar nosso cliente do cluster diretamente
context.resources.dask_cluster("...")
E é isso, agora temos integração total entre Dagster, Dask e Coiled. De uma forma muito fácil de configurar e manter.
Como bônus, é assim que definimos um cluster Dask local para fins de desenvolvimento e teste:
from dagster import resource
from contextlib import contextmanager
from dask.distributed import Client, LocalCluster
@resource
@contextmanager
def dask_local_cluster_resource(context):
'''Yields a local Dask cluster client.'''
with LocalCluster() as cluster:
with cluster.get_client() as client:
context.log.info(
f"Cluster criado, dashboard link: {client.dashboard_link}"
)
yield client
Resultados
Agora temos em nossas operações no Dagster que recebem uma tag especificando que aquela operação utiliza o Dask+Coiled. Quando o Dagster os executa, ele inicia um cluster Dask temporário, realizam o processamento necessário e, em seguida, automaticamente descarta o cluster.
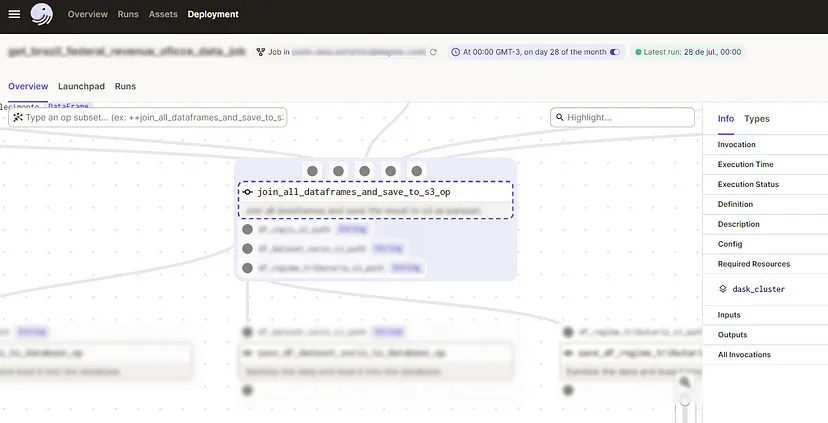
Esta imagem mostra como os recursos da operação ficam listados na UI do Dagster:
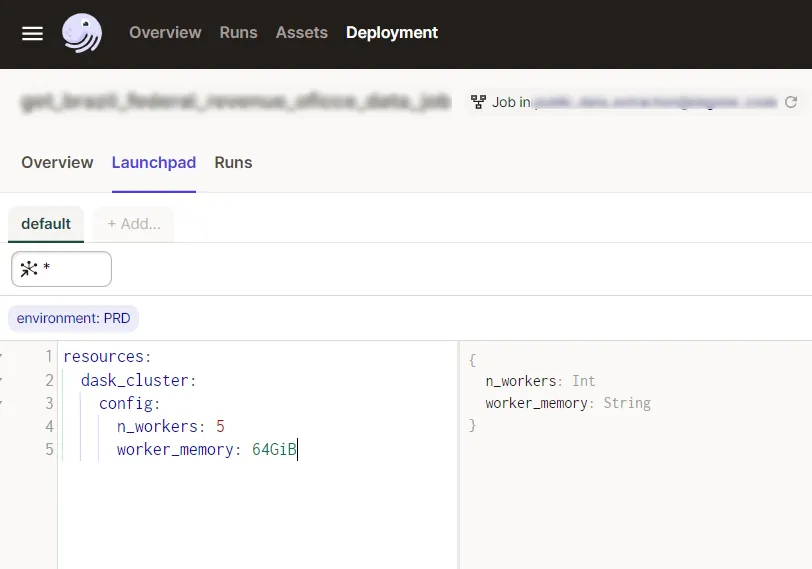
E este é o Launchpad do Dagster, aqui podemos alterar diversas configurações antes de executar nosso job, e uma delas, graças à definição do nosso cluster Coiled como um recurso, é escolher o tamanho do nosso cluster, de forma simples e parametrizada:
Agora podemos usar nossa infraestrutura existente para lidar com conjuntos de dados muito maiores do que os que usávamos anteriormente. Tudo foi muito fácil e barato.
Em conclusão
Neste artigo, examinamos um exemplo de como usar Dagster e Dask+Coiled para orquestrar um pipeline recorrente de processamento de dados. Com Dask e Coiled, conseguimos processar os dados em paralelo usando um cluster de VMs na nuvem. O Dagster é capaz de aproveitar esses recursos da nuvem, permitindo-nos processar conjuntos de dados muito maiores do que poderíamos processar de outra forma.
Espero que outras pessoas que desejam escalar seus jobs do Dagster para a nuvem considerem este artigo útil. Para obter mais informações sobre como começar a usar o Coiled, confira o guia de primeiros passos deles.
– Este artigo é uma tradução, em português, do post original. –

