Gerenciar o schema de tabelas e views em bancos de dados com rastreabilidade (controle de versões) e confiabilidade é um problema que várias ferramentas já tentaram resolver ao longo dos anos. No mundo do desenvolvimento de software, atualmente a abordagem mais comum é utilizar algum tipo de ORM (Object-Relational Mapping), que mapeia as estruturas de dados presentes no seu código (classes geralmente) para tabelas no banco de dados.
Alguns exemplos famosos são: Entity Framework no C#, SQLAlchemy no Python e o Prisma no Node.js.
Porem no mundo da ciência de dados ainda não temos um padrão definido sobre como abordar esse problema, isso se da por vários fatores, o principal deles é que utilizar um ORM tradicional geralmente não faz muito sentido por ser limitado em alguns casos, não dando “liberdade total” ao modificar as estruturas de dados (views principalmente) e também optimizações (principalmente em bancos OLAP).
Uma das ferramentas que visa resolver esse problema e que tem se fortalecido muito recentemente é nosso querido DBT. Ele é realmente uma ferramente incrível com um grande potencial, porem como nosso amigo Benn Stancil disse em um recente artigo:
"Ferramentas de orquestração como Dagster sobressaem o dbt com ambientes de desenvolvimento explicitamente criados para criar pipelines de dados multifonte, multidestino e poliglotas. Eles foram capazes de copiar as partes amadas do dbt Core mais rapidamente do que o dbt Labs foi capaz de adicionar programação dinâmica, suporte robusto para Python e outros elementos que as pessoas queriam em sua camada de transformação."
Benn Stancil, How dbt fails
Devo dizer que concordo 100% com tudo que Benn disse, e por isso decidi mostrar como utilizo o Dagster no meu dia a dia para gerenciar essas estruturas em meus bancos de dados.
Preparando nosso ambiente
Criando um banco de dados Postgres
Iremos utilizar o neon.tech para a hospedagem de um banco de dados Postgres, a Neon oferece um incrível serviço de hospedagem Serverless com um plano grátis incrível.
Apos a criação do banco (não entrarei em detalhes, pois é super intuitivo e simples) iremos carregar um dataset de venda de produtos para realizar nossos testes. Você pode encontrá-lo neste link: relational.fit.cvut.cz/dataset/SalesDB.
Segue abaixo o schema de tabelas deste dataset.
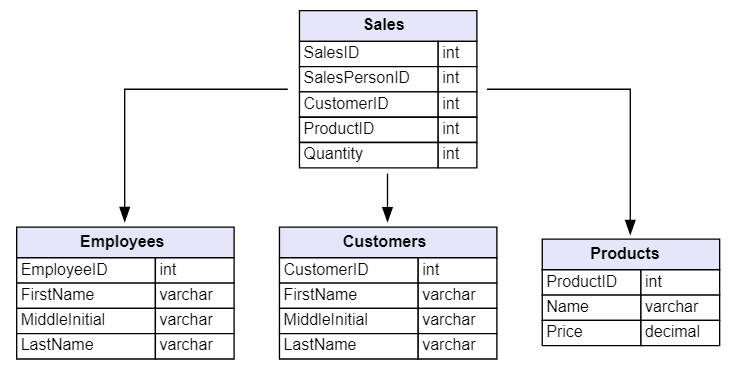
**Nota: Alterei os nomes dos campos do dataset original de Camel case para Snake case.
Instalando e Configurando o Dagster
Para manter o artigo sucinto irei apenas adicionar as principais partes do código aqui, o código completo esta disponível em meu GitHub neste link.
Primeiramente vamos definir nosso resource de conexão com o banco de dados, podemos definir um resource no Dagster como sendo um objeto que abstrair algum recurso externo, como uma conexão com banco de dados (nesse caso) ou uma API.
Segue abaixo o código do nosso recurso:
from sqlalchemy import create_engine
from contextlib import contextmanager
from dagster import resource
import os
@resource
@contextmanager
def postgres_connection(context):
''' Return a Postgres connection. '''
database_url: str = os.getenv('DATABASE_URL')
assert database_url is not None, 'DATABASE_URL Environment variable not set.'
engine = create_engine(database_url)
with engine.begin() as connection:
yield connection
Agora vamos definir nosso repository, ele serve como uma coleção de assets, jobs, schedules e sensores. São uma maneira conveniente de organizar seus diferentes jobs e outras definições em diferentes repositórios.
Também iremos criar um sensor de reconciliação de assets, ele que ira fazer a mágica de automaticamente propagar nossas atualizações de schema para os assets dependentes.
from dagster import repository, build_asset_reconciliation_sensor, AssetSelection
from repositories import *
assets_reconciliation_sensor = build_asset_reconciliation_sensor(
asset_selection=AssetSelection.all(),
name='assets_reconciliation_sensor'
)
@repository
def postgres():
''' This repository is responsible for all jobs and assets related to Postgres. '''
return [
postgres_assets,
assets_reconciliation_sensor
]
Nas linhas 2 e 16 estamos importando e adicionando nossos assets no repositório, receptivamente, logo abaixo iremos definir esses assets.
Criando Nosso Primeiro Asset no Dagster
Primeiramente vamos criar os assets contendo o DDL de criação de nossas tabelas. Podemos fazer isso da seguinte forma:
from dagster import asset, Output, MetadataValue
import pathlib
@asset(
required_resource_keys={'postgres'},
name='costumers',
compute_kind='postgres',
)
def costumers_asset(context):
''' Asset for table "costumers" in the Postgres Database. '''
with open(f'{pathlib.Path(__file__).parent}/sql/ddl.sql', 'r') as file:
ddl = file.read()
context.log.info(f'Creating table "costumers".')
context.resources.postgres.execute(ddl)
return Output(
None,
metadata={
'DDL': MetadataValue.md(f'```\n{ddl}\n```')
}
)
O conteúdo do arquivo “sql/ddl.sql” é o seguinte:
CREATE TABLE IF NOT EXISTS public.customers (
customer_id int8 PRIMARY KEY,
first_name varchar(40) NOT NULL,
middle_initial varchar(40) NULL,
last_name varchar(40) NOT NULL
)
Após repetir o processo para as demais tabelas (você pode encontrar o código completo em meu GitHub) vamos agora atribuir os recursos necessários que definimos na criação de nossos assets, nesse caso nossa conexão com o Postgres, podemos fazer isso da seguinte forma:
from resources import postgres
from dagster import with_resources
import os
from .costumers import costumers_asset
from .employees import employees_asset
from .products import products_asset
from .sales import sales_asset
postgres_assets = with_resources(
[
costumers_asset,
employees_asset,
products_asset,
sales_asset
],
resource_defs={
'postgres': postgres.postgres_connection,
},
)
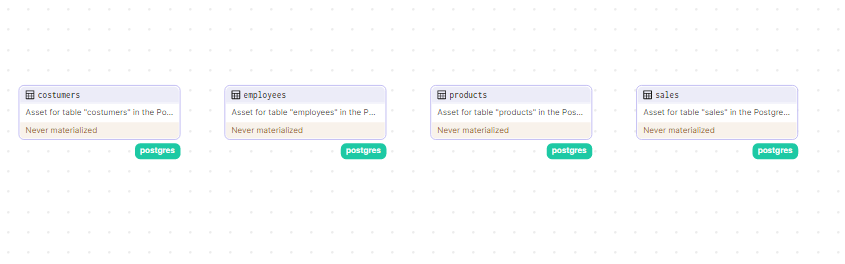
Pronto, até o momento temos os seguintes assets no Dagster:
Porem se tentarmos criar nossos assets agora teríamos que criar manualmente as tabelas na ordem correta para evitar erros devido às chaves estrangeiras, vamos corrigir isso definindo as dependências nas tabelas que contem chaves estrangeiras, no caso a tabela “sales”, podemos fazer isso adicionando o seguinte trecho de código na definição do asset:
...
non_argument_deps={
'products': AssetIn(key='products'),
'costumers': AssetIn(key='costumers'),
'employees': AssetIn(key='employees'),
}
...
Prontinho, agora podemos materializar (executar) nossos assets sem nos preocupar com as dependências entre as tabelas.
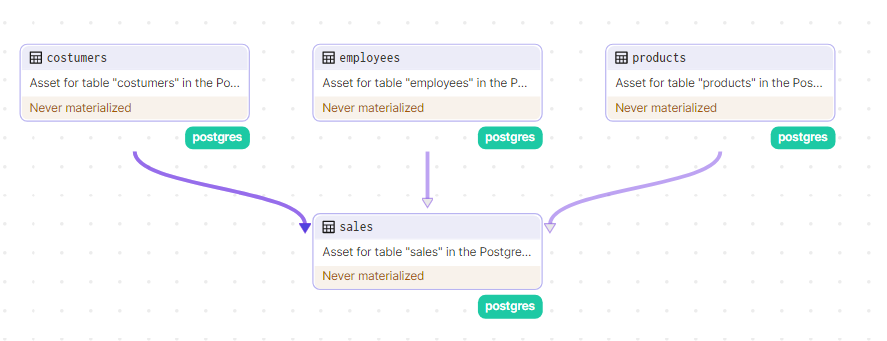
Abaixo uma GIF do processo de materialização dos assets até o momento:
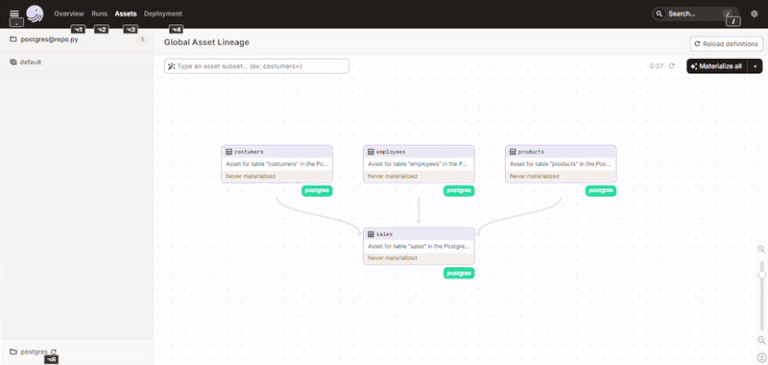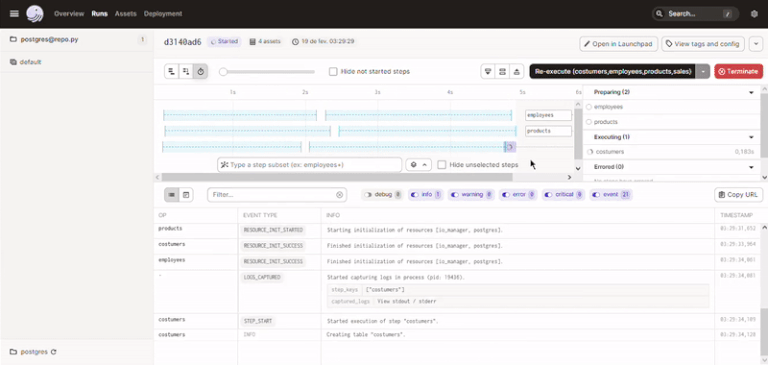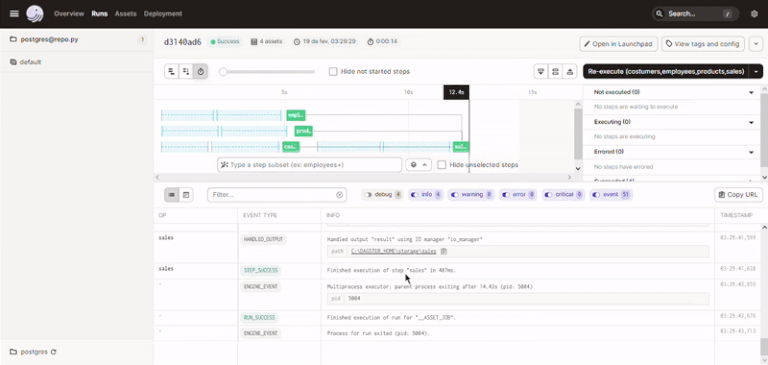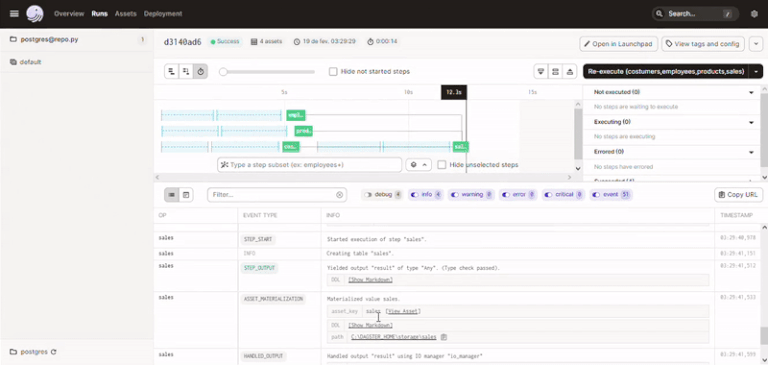
Apos isso fiz o carregamento dos dados nas tabelas de forma manual, mas nada impediria de criarmos um job no Dagster que faça isso para nos de forma automática.
Criando os assets para as views
Nossas tabelas foram modeladas utilizando ‘Star Schema‘, aonde temos as tabelas dimensão, “employees”, “products” e “costumers” e a tabela fato “sales”, porem vamos criar agora uma view aonde conseguimos ter uma visão desnormalizada dos dados. Segue abaixo a consulta que usaremos para criar essa view.
CREATE OR REPLACE VIEW view_sales_full AS
SELECT
sales.sales_id,
employees.employee_id,
concat(employees.first_name, ' ', employees.middle_initial, '. ', employees.last_name) AS employee_full_name,
customers.customer_id,
concat(customers.first_name, ' ', customers.middle_initial, '. ', customers.last_name) AS customer_full_name,
products.product_id,
products."name" AS product_name,
products.price AS product_price,
sales.quantity AS product_quantity
FROM
sales INNER JOIN employees ON
sales.salesperson_id = employees.employee_id
INNER JOIN products ON
sales.product_id = products.product_id
INNER JOIN customers ON
sales.customer_id = customers.customer_id
A consulta da view acima nos retorna o seguinte resultado:

Agora vamos definir o asset para gerenciar essa view. Segue o código abaixo:
from dagster import asset, Output, AssetIn, MetadataValue
import pathlib
@asset(
required_resource_keys={'postgres'},
name='view_sales_full',
compute_kind='postgres',
non_argument_deps={
'products': AssetIn(key='products'),
'costumers': AssetIn(key='costumers'),
'employees': AssetIn(key='employees'),
'sales': AssetIn(key='sales'),
}
)
def view_sales_full_asset(context):
''' Asset for view "view_sales_full" in the Postgres Database. '''
with open(f'{pathlib.Path(__file__).parent}/sql/ddl.sql', 'r') as file:
ddl = file.read()
context.log.info('Droping view "view_sales_full".')
context.resources.postgres.execute('DROP VIEW IF EXISTS view_sales_full CASCADE')
context.log.info(f'Creating view "view_sales_full".')
context.resources.postgres.execute(ddl)
return Output(
None,
metadata={
'DDL': MetadataValue.md(f'```\n{ddl}\n```')
}
)
Após definidos esse é todo o nosso fluxo até o momento.
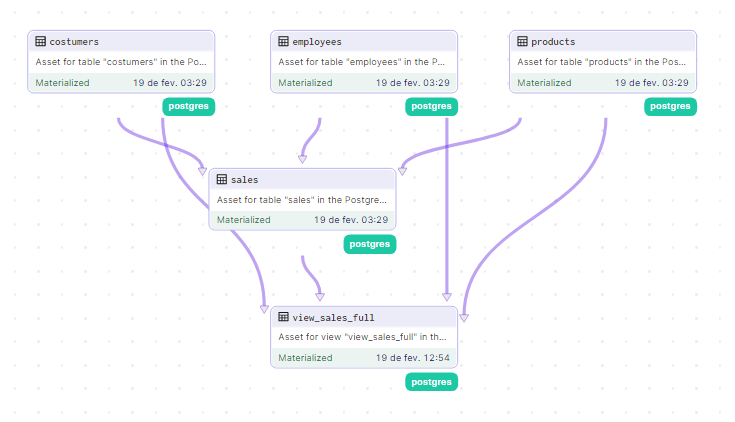
Acredito que vocês entenderam o conceito, não existe limite de quantas views e tabelas dependentes podemos criar a partir daqui.
Conclusão
O Dagster é realmente uma ferramenta de orquestração incrível, que traz conceitos sensacionais como os assets, sendo muito mais complexos do que foi mostrado aqui, contando com particionamentos, DAGs internas para assets mais complexos, freshness policy e muito mais. E por esse e outros motivos, sempre opto por utilizá-lo ao invés de ferramentas mais engessadas como, por exemplo, o Airflow.
Dagster VS DBT ?
Vale lembrar que apesar do título sensacionalista do artigo, você não, não precisa escolher dentre uma ferramenta ou outra, uma das grandes vantagens do Dagster é que seus assets podem ser literalmente qualquer coisa, inclusive modelos do DBT. O Dagster tem sido muito utilizado pela comunidade como um orquestrador para o DBT.
Você pode encontrar mais detalhes neste artigo que o próprio Dagster publicou.
Mas, me diga sua opinião, se fosse para escolher dentre o DBT e Dagster qual escolheria, ou utilizaria os dois em conjunto? Deixe sua opinião comentários abaixo!
