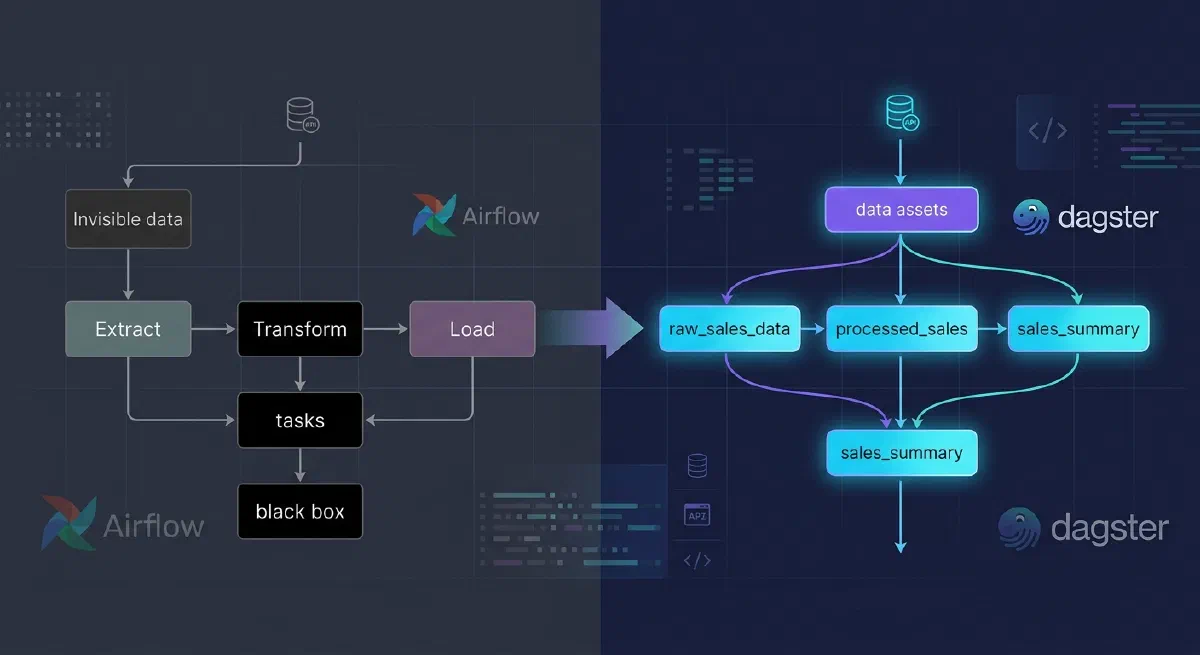
If you work in data engineering, you’ve probably grown tired of thinking about pipelines as a sequence of tasks: Extract → Transform → Load. But what if I told you that’s not the best way to model your data? Dagster revolutionized how we think about data orchestration with a simple yet powerful concept: Software-Defined Assets.
The Problem with Traditional ETL
In the traditional ETL model, we think in terms of processes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# Traditional approach - focused on TASKS
def extract_data():
"""Extracts data from the API"""
data = requests.get('https://api.example.com/sales')
return data.json()
def transform_data(raw_data):
"""Transforms the data"""
df = pd.DataFrame(raw_data)
df['total'] = df['quantity'] * df['price']
return df
def load_data(df):
"""Loads into the database"""
df.to_sql('sales', engine, if_exists='replace')
# Pipeline focused on EXECUTING tasks
def etl_pipeline():
raw = extract_data()
transformed = transform_data(raw)
load_data(transformed)
|
What’s wrong with this?
- You don’t know WHERE your data is — only that you executed tasks
- No clear lineage — hard to trace where each piece of data comes from
- Re-runs are complicated — you need to run everything again
- Tests are hard — you test processes, not data
- Lack of visibility — you see that a task ran, but don’t know the state of the data
The Revolution: Thinking in Assets, Not Tasks
Dagster proposes a fundamental shift: think about WHAT you want (the data) and not HOW to do it (the tasks).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import dagster as dg
import pandas as pd
import requests
@dg.asset
def raw_sales_data() -> pd.DataFrame:
"""Raw sales data from the API"""
response = requests.get('https://api.example.com/sales')
return pd.DataFrame(response.json())
@dg.asset
def processed_sales(raw_sales_data: pd.DataFrame) -> pd.DataFrame:
"""Processed sales with total calculation"""
df = raw_sales_data.copy()
df['total'] = df['quantity'] * df['price']
df['processed_at'] = pd.Timestamp.now()
return df
@dg.asset
def sales_summary(processed_sales: pd.DataFrame) -> pd.DataFrame:
"""Daily sales summary"""
return processed_sales.groupby(
pd.Grouper(key='date', freq='D')
).agg({
'total': 'sum',
'quantity': 'sum',
'order_id': 'count'
}).reset_index()
|
See the difference! Now:
- ✅ Each function defines ONE DATA (asset)
- ✅ Dependencies are explicit (through parameters)
- ✅ Dagster builds the graph automatically
- ✅ You can materialize assets individually
- ✅ Lineage is clear and traceable
How It Works in Practice
1. Defining a Simple Asset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import dagster as dg
@dg.asset
def customers_data(context: dg.AssetExecutionContext):
"""List of active customers"""
context.log.info("Loading customer data...")
customers = [
{"id": 1, "name": "John Silva", "status": "active"},
{"id": 2, "name": "Mary Santos", "status": "active"},
{"id": 3, "name": "Peter Costa", "status": "inactive"},
]
active_customers = [c for c in customers if c['status'] == 'active']
context.log.info(f"Found {len(active_customers)} active customers")
return active_customers
|
2. Creating Dependencies Between Assets
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import dagster as dg
import pandas as pd
@dg.asset
def orders_raw() -> pd.DataFrame:
"""Raw orders from the database"""
return pd.DataFrame({
'order_id': [1, 2, 3, 4],
'customer_id': [1, 1, 2, 3],
'amount': [100.0, 150.0, 200.0, 75.0],
'date': pd.date_range('2026-04-01', periods=4)
})
@dg.asset
def customers() -> pd.DataFrame:
"""Customer data"""
return pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John Silva', 'Mary Santos', 'Peter Costa'],
'segment': ['Premium', 'Standard', 'Premium']
})
@dg.asset
def enriched_orders(orders_raw: pd.DataFrame, customers: pd.DataFrame) -> pd.DataFrame:
"""Orders enriched with customer data"""
return orders_raw.merge(customers, on='customer_id', how='left')
@dg.asset
def revenue_by_segment(enriched_orders: pd.DataFrame) -> pd.DataFrame:
"""Total revenue by customer segment"""
return enriched_orders.groupby('segment')['amount'].sum().reset_index()
|
Dagster automatically understands that:
enriched_orders depends on orders_raw AND customersrevenue_by_segment depends on enriched_orders- If you update
customers, enriched_orders and revenue_by_segment become stale
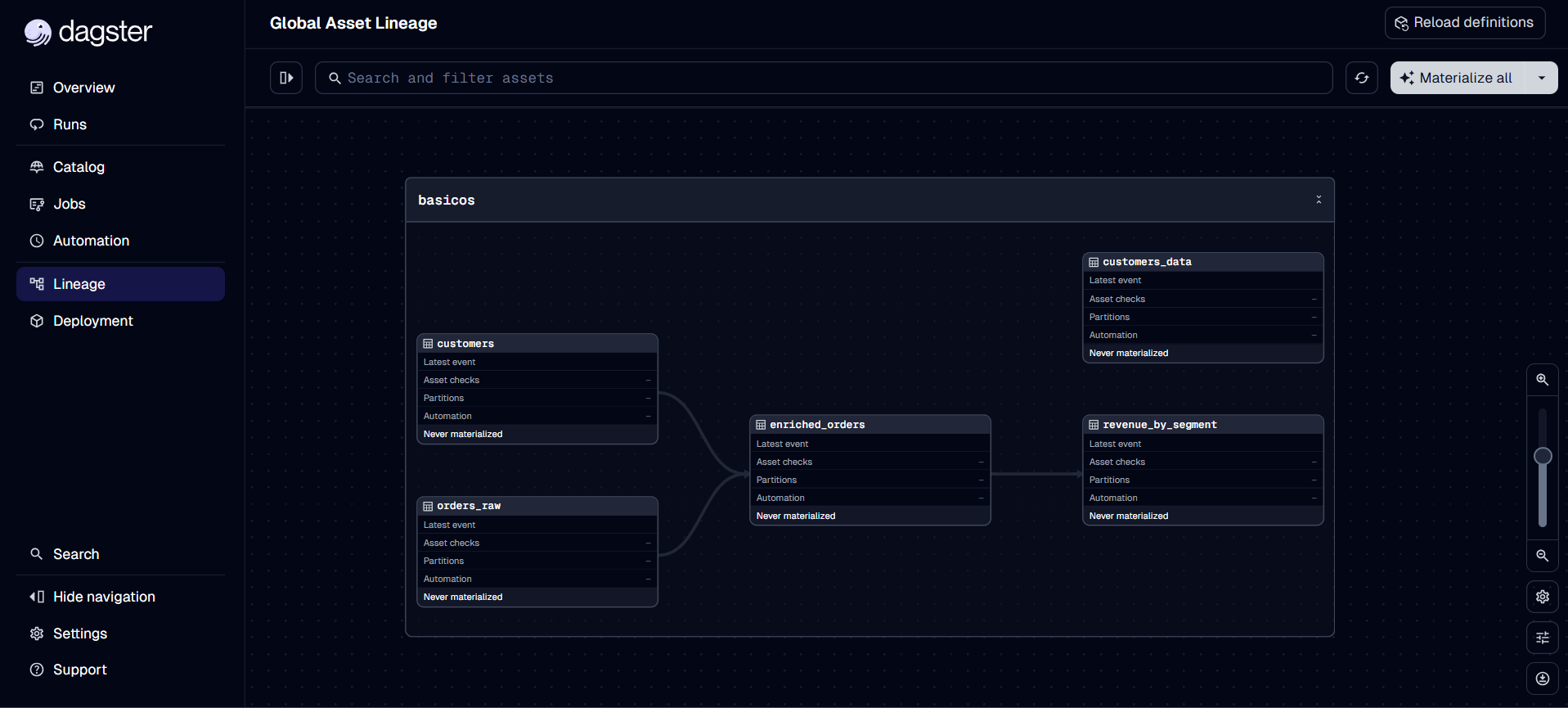
3. Multi-Assets: Multiple Assets from a Single Operation
Sometimes you make ONE call that returns MULTIPLE pieces of data. Use @multi_asset:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import dagster as dg
@dg.multi_asset(
specs=[
dg.AssetSpec("users"),
dg.AssetSpec("posts"),
dg.AssetSpec("comments")
]
)
def extract_from_api(context: dg.AssetExecutionContext):
"""Fetches data from multiple entities in a single API call"""
context.log.info("Making single call to API...")
api_response = {
'users': [{'id': 1, 'name': 'John'}],
'posts': [{'id': 1, 'user_id': 1, 'title': 'Hello'}],
'comments': [{'id': 1, 'post_id': 1, 'text': 'Nice!'}]
}
yield dg.MaterializeResult(asset_key="users", metadata={"count": len(api_response['users'])})
yield dg.MaterializeResult(asset_key="posts", metadata={"count": len(api_response['posts'])})
yield dg.MaterializeResult(asset_key="comments", metadata={"count": len(api_response['comments'])})
|
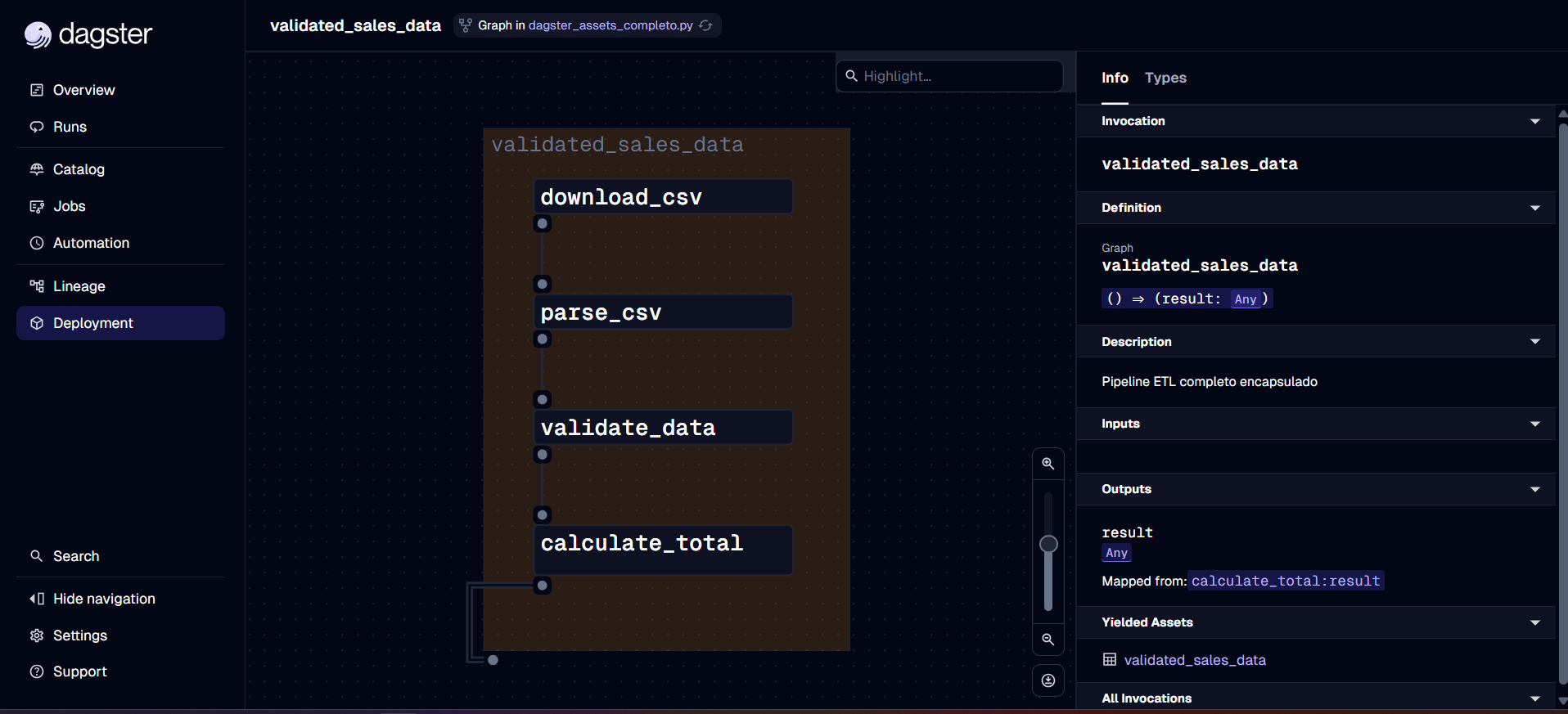
4. Graph Assets: Multiple Operations for One Asset
When you need several intermediate steps but only want to expose the final result (see more at Graph-backed assets):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import dagster as dg
@dg.op
def download_csv(context: dg.OpExecutionContext) -> str:
context.log.info("Downloading file...")
return "s3://bucket/data.csv"
@dg.op
def parse_csv(context: dg.OpExecutionContext, file_path: str) -> list:
context.log.info(f"Parsing {file_path}")
return [{"col1": "val1"}, {"col1": "val2"}]
@dg.op
def validate_data(context: dg.OpExecutionContext, data: list) -> list:
context.log.info(f"Validating {len(data)} records")
return data
@dg.graph_asset
def validated_sales_data():
"""Final asset that encapsulates the entire process"""
file = download_csv()
parsed = parse_csv(file)
return validate_data(parsed)
|
Defining Modern Jobs with Assets
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import dagster as dg
@dg.asset
def bronze_sales():
return {"status": "raw"}
@dg.asset
def silver_sales(bronze_sales):
return {"status": "cleaned"}
@dg.asset
def gold_sales(silver_sales):
return {"status": "aggregated"}
all_assets_job = dg.define_asset_job(
name="materialize_all_sales",
selection=dg.AssetSelection.all()
)
defs = dg.Definitions(
assets=[bronze_sales, silver_sales, gold_sales],
jobs=[all_assets_job]
)
|
Real Example: E-commerce Pipeline
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
import dagster as dg
import pandas as pd
@dg.asset(group_name="bronze")
def bronze_orders(context: dg.AssetExecutionContext) -> pd.DataFrame:
"""Raw orders from the e-commerce API"""
orders = pd.DataFrame({
'order_id': range(1, 101),
'customer_id': [i % 20 for i in range(1, 101)],
'product_id': [i % 10 for i in range(1, 101)],
'quantity': [1, 2, 1, 3] * 25,
'price': [99.90, 149.90, 199.90, 299.90] * 25,
'created_at': pd.date_range('2026-03-01', periods=100, freq='h')
})
context.add_output_metadata({"num_orders": len(orders)})
return orders
@dg.asset(group_name="silver")
def silver_orders_enriched(
bronze_orders: pd.DataFrame,
bronze_products: pd.DataFrame,
bronze_customers: pd.DataFrame
) -> pd.DataFrame:
"""Orders enriched with product and customer data"""
enriched = bronze_orders.copy()
enriched['total'] = enriched['quantity'] * enriched['price']
enriched = enriched.merge(bronze_products[['product_id', 'name', 'category']], on='product_id', how='left')
enriched = enriched.merge(bronze_customers[['customer_id', 'city', 'segment']], on='customer_id', how='left')
return enriched
@dg.asset(group_name="gold")
def gold_daily_revenue(silver_orders_enriched: pd.DataFrame) -> pd.DataFrame:
"""Aggregated daily revenue"""
return silver_orders_enriched.groupby(
silver_orders_enriched['created_at'].dt.date
).agg({'total': 'sum', 'order_id': 'count'}).reset_index()
|
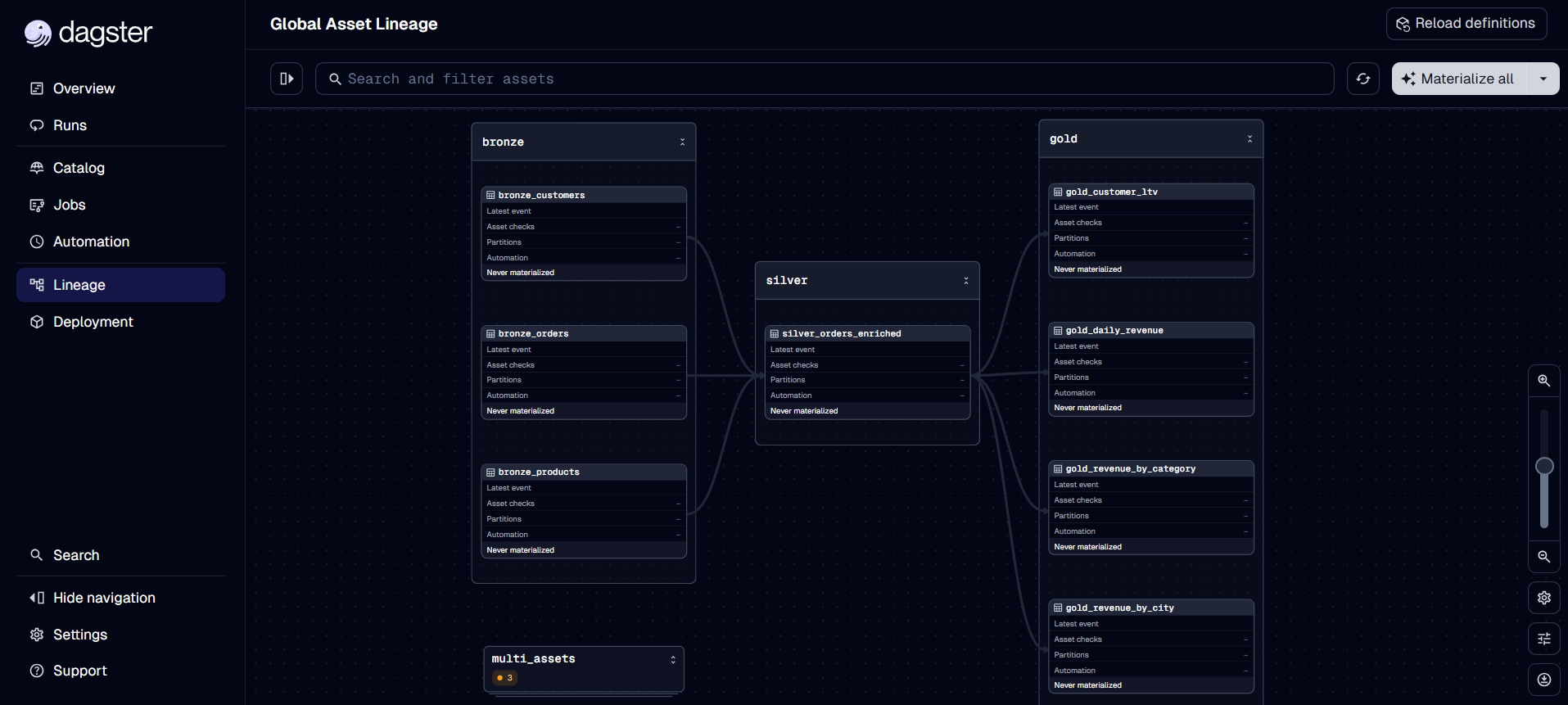
Benefits of the Asset-First Approach
1. Automatic Lineage
Dagster automatically creates a dependency graph showing where each piece of data comes from.
2. Selective Materialization
Need to update just one asset? Just materialize it:
1
|
dg.materialize([gold_revenue_by_category])
|
1
2
3
4
5
6
7
8
9
|
@dg.asset
def sales_report(context: dg.AssetExecutionContext):
df = compute_sales()
context.add_output_metadata({
"num_rows": len(df),
"revenue_total": df['total'].sum(),
"preview": dg.MetadataValue.md(df.head().to_markdown())
})
return df
|
4. Easier Testing
1
2
3
4
5
6
7
8
|
def test_revenue_calculation():
fake_orders = pd.DataFrame({'quantity': [2, 3], 'price': [10.0, 20.0]})
result = silver_orders_enriched(
bronze_orders=fake_orders,
bronze_products=pd.DataFrame(),
bronze_customers=pd.DataFrame()
)
assert result['total'].tolist() == [20.0, 60.0]
|
Conclusion
The paradigm shift from traditional ETL to Software-Defined Assets is not just a syntax change — it’s a fundamental change in how to think about data:
- From: “I execute tasks that move data”
- To: “I define data and Dagster handles execution”
This brings:
- ✅ Greater clarity: you know exactly what data exists
- ✅ Better traceability: automatic lineage
- ✅ Flexibility: materialize only what you need
- ✅ Testability: pure functions are easy to test
- ✅ Observability: rich metadata and visual graph
If you’re still thinking about pipelines as sequences of tasks, it’s time to make the switch. The future of data engineering is asset-centric, not task-centric.
For a deeper dive, explore the official Dagster documentation and the GitHub repository.