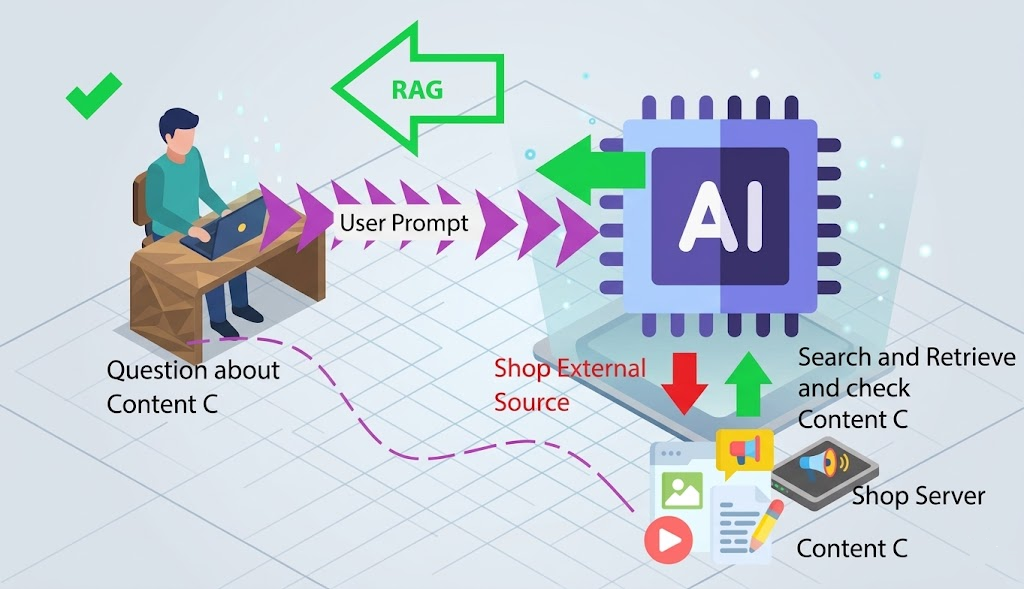
A geração de texto com modelos de linguagem grandes (LLMs) tem revolucionado a forma como criamos conteúdo. No entanto, um dos maiores desafios é garantir que as informações geradas sejam verificáveis e confiáveis. Neste artigo, vou mostrar uma técnica universal para gerar qualquer tipo de conteúdo estruturado com referências verificáveis, combinando busca avançada (Tavily) com LLMs. Usarei biografias como exemplo prático, mas a técnica se aplica a relatórios, artigos, análises e qualquer outro conteúdo baseado em fatos.
O Problema: Alucinações em LLMs
LLMs são incríveis para gerar textos coerentes e bem escritos, mas frequentemente “alucinam” - inventam informações que parecem plausíveis mas não são verdadeiras. A solução? Fornecer ao modelo informações verificadas e exigir que ele cite suas fontes para cada afirmação.
A Solução: Busca + Geração Estruturada
Vamos construir um sistema que: 1. Busca informações reais sobre um tópico usando a API Tavily 2. Usa um LLM com suporte a saída estruturada (neste exemplo, Google Gemini) para gerar um texto estruturado 3. Exige que cada sentença do texto tenha uma referência específica
Nota importante: Qualquer provedor de LLM que suporte saída estruturada pode ser usado nesta abordagem - OpenAI, Anthropic, Google, Azure OpenAI, etc. O princípio é o mesmo: fornecer um schema JSON e exigir que o modelo retorne dados nesse formato.
Instalação das Dependências
Primeiro, precisamos instalar as bibliotecas necessárias:
|
|
Buscando Informações com Tavily
A Tavily é uma API de busca otimizada para agentes de IA e RAG (Retrieval-Augmented Generation). Ao contrário de APIs de busca tradicionais, ela retorna conteúdo limpo e estruturado ideal para alimentar LLMs.
Para este exemplo, vamos buscar informações sobre um artista para criar uma biografia, mas você pode adaptar a query para qualquer tópico:
|
|
O parâmetro search_depth="advanced" faz com que a Tavily realize uma busca mais profunda e precisa, essencial para obter informações confiáveis.
Estruturando a Resposta com Pydantic
Para garantir que o LLM retorne dados no formato que precisamos, usamos Pydantic para definir a estrutura esperada. A estrutura abaixo é específica para biografias, mas você pode criar estruturas similares para qualquer tipo de conteúdo (relatórios, artigos de pesquisa, análises de mercado, etc.):
|
|
Esta estrutura garante que:
- Cada sentença (Sentence) tenha um texto e uma referência
- Cada referência (Reference) contenha título, URL e um trecho que suporta a informação
- A biografia completa (ArtistBiography) seja uma lista de sentenças estruturadas
Gerando o Conteúdo com LLM e Saída Estruturada
Agora vamos construir o prompt e usar um LLM para gerar o conteúdo. Neste exemplo, usamos o Google Gemini para gerar uma biografia, mas qualquer modelo que suporte structured output funcionaria (OpenAI com response_format, Anthropic Claude, etc.) e você pode adaptar o prompt para gerar qualquer tipo de conteúdo:
|
|
Agora chamamos o Gemini com o schema JSON da nossa estrutura Pydantic:
|
|
O parâmetro response_schema é o segredo aqui - ele força o modelo a retornar dados exatamente no formato que definimos com Pydantic.
Alternativas de Provedores
Você pode usar outros provedores de LLM com abordagens similares:
OpenAI:
|
|
Anthropic Claude:
|
|
O importante é que o provedor escolhido suporte a geração de saída estruturada em JSON.
Exibindo o Resultado
Por fim, podemos exibir a biografia gerada com suas referências:
|
|
Resultado Esperado
O código acima vai gerar uma saída como:
# Silvio Santos
Silvio Santos, nome artístico de Senor Abravanel, nasceu em 12 de dezembro de 1930 no Rio de Janeiro.
>Reference: Silvio Santos - Wikipedia - https://pt.wikipedia.org/wiki/Silvio_Santos
>Excerpt: Senor Abravanel, mais conhecido como Silvio Santos, nasceu em 12 de dezembro de 1930...
Foi um dos maiores apresentadores e empresários da televisão brasileira...
>Reference: A trajetória de Silvio Santos - Portal G1
>Excerpt: O apresentador construiu um império na TV brasileira...
Por Que Isso é Importante?
Esta abordagem resolve vários problemas comuns na geração de texto com IA:
- Rastreabilidade: Cada afirmação tem uma fonte verificável
- Confiabilidade: As informações vêm de buscas reais, não da memória do LLM
- Estruturação: O formato Pydantic garante dados consistentes
- Verificação: Usuários podem clicar nos links e verificar as informações
Casos de Uso
Esta técnica pode ser aplicada em diversos cenários:
- Geração de relatórios de pesquisa
- Criação de artigos jornalísticos
- Resumos executivos com fontes
- Fichas técnicas de produtos
- Análises de mercado documentadas
Conclusão
Combinar busca avançada com geração estruturada nos permite criar sistemas de IA que são tanto criativos quanto confiáveis. A técnica demonstrada aqui com biografias é apenas um exemplo - você pode adaptar o mesmo padrão para:
- Relatórios técnicos: Cada parágrafo com referências a documentação oficial
- Artigos de opinião: Argumentos suportados por estudos e notícias
- Resumos de pesquisa: Insights extraídos de múltiplos papers acadêmicos
- Análises de produtos: Características verificadas com fontes oficiais
- Conteúdo educacional: Conceitos explicados com referências confiáveis
O princípio é sempre o mesmo: buscar informações verificadas, estruturar os dados com Pydantic, e exigir que cada afirmação tenha uma fonte. Isso reduz drasticamente o problema de alucinações em LLMs.
Recursos Adicionais
Gostou do artigo? Tem alguma dúvida ou sugestão? Entre em contato!