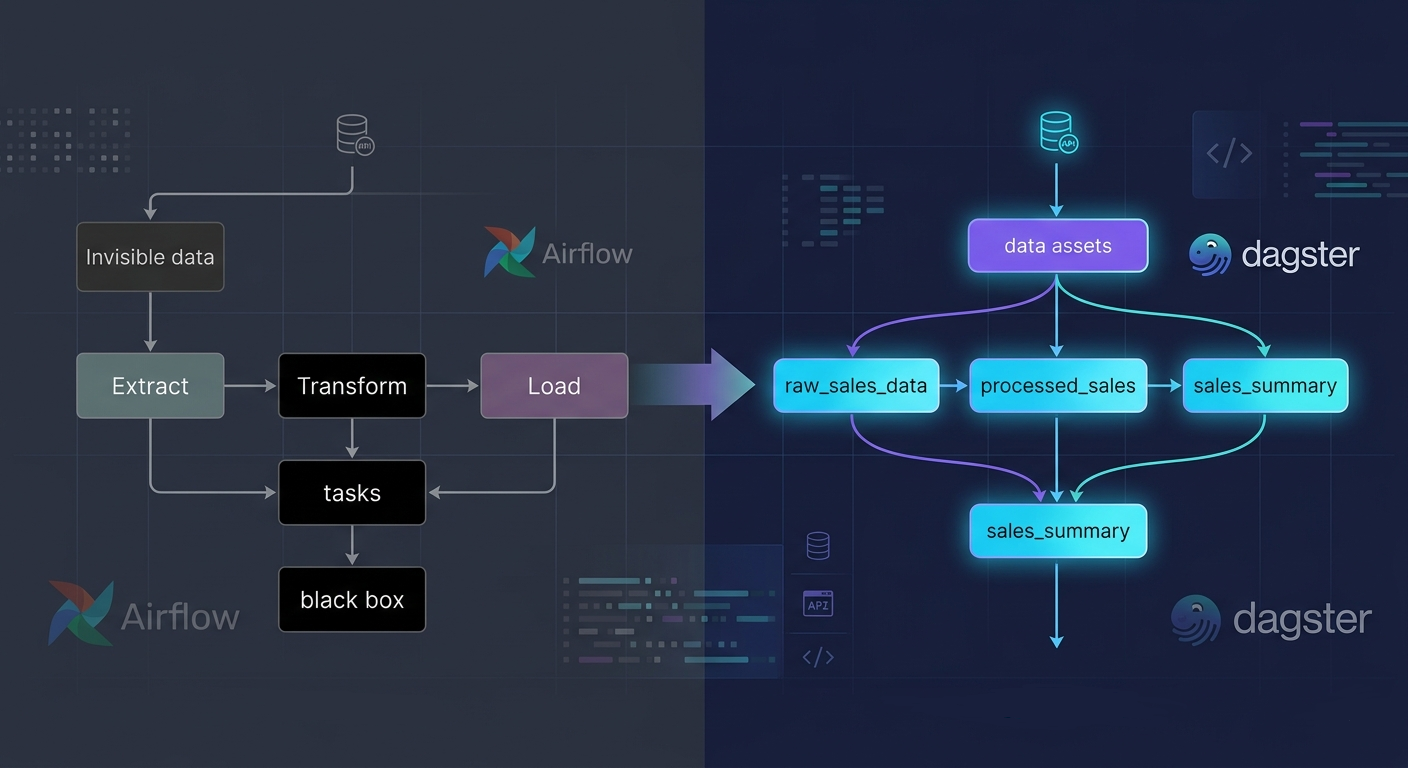
Se você trabalha com engenharia de dados, provavelmente já está cansado de pensar em pipelines como uma sequência de tarefas: Extract → Transform → Load. Mas e se eu te disser que essa não é a melhor forma de modelar seus dados? O Dagster revolucionou a forma como pensamos sobre orquestração de dados com um conceito simples, porém poderoso: Software-Defined Assets.
O Problema com ETL Tradicional
No modelo tradicional de ETL, pensamos em processos:
|
|
Qual o problema com isso?
- Você não sabe ONDE seus dados estão - apenas que executou tarefas
- Não há linhagem clara - difícil rastrear de onde vem cada dado
- Re-execuções são complicadas - precisa rodar tudo de novo
- Testes são difíceis - você testa processos, não dados
- Falta visibilidade - você vê que uma tarefa rodou, mas não sabe o estado do dado
A Revolução: Pensando em Assets, Não em Tasks
O Dagster propõe uma mudança fundamental: pense no QUE você quer (os dados) e não no COMO fazer (as tarefas).
|
|
Veja a diferença! Agora:
- ✅ Cada função define UM DADO (asset)
- ✅ As dependências são explícitas (através dos parâmetros)
- ✅ O Dagster constrói o grafo automaticamente
- ✅ Você pode materializar assets individualmente
- ✅ A linhagem é clara e rastreável
Como Funciona na Prática
1. Definindo um Asset Simples
|
|
2. Criando Dependências Entre Assets
|
|
O Dagster automaticamente entende que:
enriched_ordersdepende deorders_rawEcustomersrevenue_by_segmentdepende deenriched_orders- Se você atualizar
customers,enriched_orderserevenue_by_segmentficam desatualizados

3. Multi-Assets: Vários Assets de Uma Única Operação
Às vezes você faz UMA chamada que retorna VÁRIOS dados. Use @multi_asset:
|
|
4. Graph Assets: Múltiplas Operações para Um Asset
Quando você precisa de várias etapas intermediárias mas só quer expor o resultado final (veja mais em Graph-backed assets):
|
|
Isso cria UM asset (validated_sales_data) mas com três operações internas que você pode monitorar separadamente.

Definindo Jobs Modernos com Assets
Agora que você tem assets, como executá-los? Com asset jobs:
|
|
Exemplo Real: Pipeline de E-commerce
Vamos criar um pipeline completo de análise de e-commerce:
|
|
Visualizando a Linhagem
O Dagster automaticamente cria um grafo visual mostrando a linhagem completa dos seus dados:
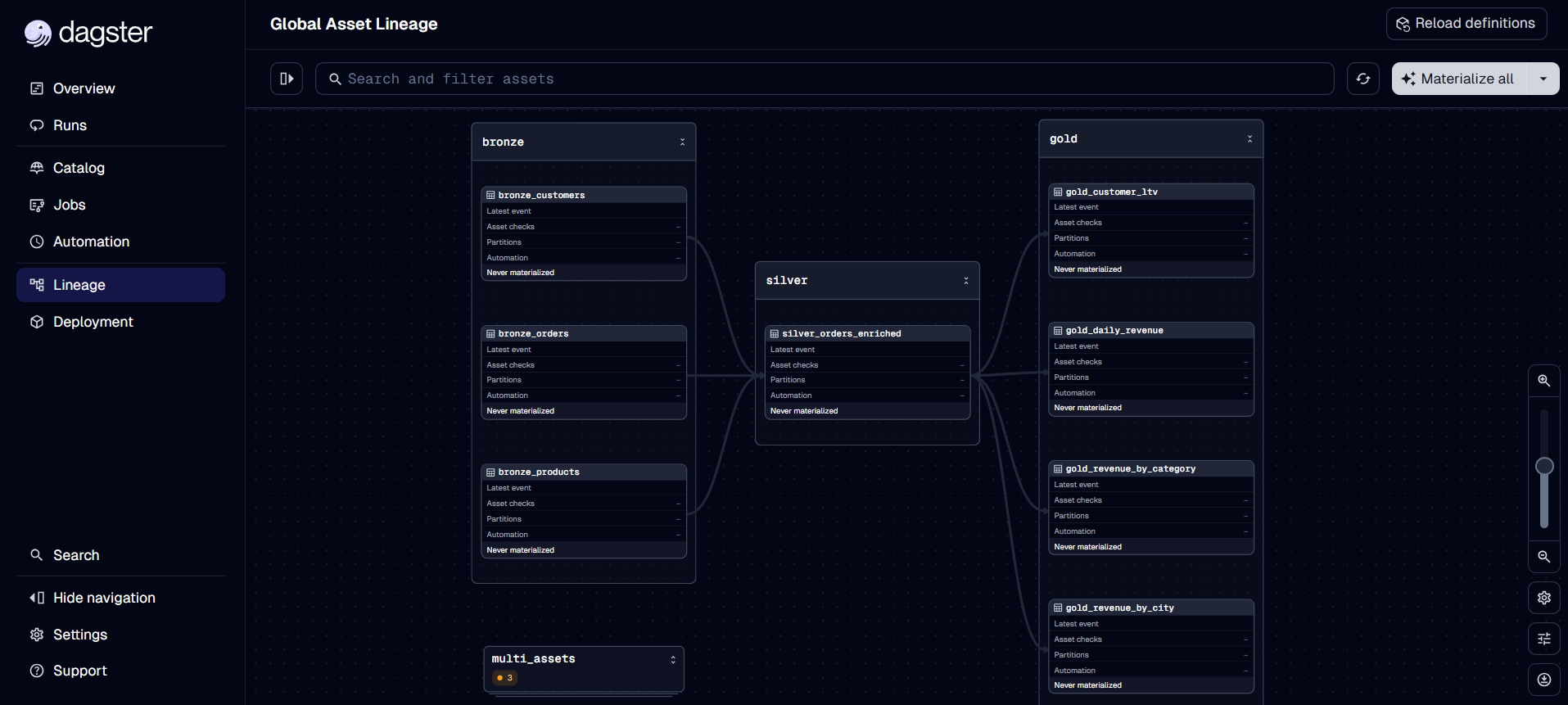
Neste grafo você pode:
- Ver todas as dependências entre assets
- Identificar qual camada cada asset pertence
- Materializar assets individuais ou por grupo
- Rastrear o impacto de mudanças upstream
Benefícios da Abordagem Asset-First
1. Linhagem Automática
O Dagster cria automaticamente um grafo de dependências mostrando de onde cada dado vem.
2. Materialização Seletiva
Precisa atualizar só um asset? Basta materializá-lo:
|
|
3. Versionamento de Código
|
|
O Dagster rastreia quando seu código muda e quais assets precisam ser re-materializados.
4. Metadata Rica
Adicione metadata aos seus assets:
|
|
5. Testes Mais Fáceis
|
|
Comparação: Antes vs Depois
❌ Abordagem Tradicional (Task-Based):
|
|
✅ Abordagem Moderna (Asset-Based):
|
|
Conclusão
A mudança de paradigma de ETL tradicional para Software-Defined Assets não é apenas uma mudança de sintaxe - é uma mudança fundamental na forma de pensar sobre dados:
- De: “Eu executo tarefas que movem dados”
- Para: “Eu defino dados e o Dagster cuida da execução”
Isso traz:
- ✅ Maior clareza: você sabe exatamente quais dados existem
- ✅ Melhor rastreabilidade: linhagem automática
- ✅ Flexibilidade: materialize só o que precisa
- ✅ Testabilidade: funções puras são fáceis de testar
- ✅ Observabilidade: metadata rica e grafo visual
Se você ainda está pensando em pipelines como sequências de tarefas, está na hora de fazer a mudança. O futuro da engenharia de dados é centrado em ativos, não em tarefas.
Para se aprofundar mais, explore a documentação oficial do Dagster e o repositório no GitHub.
Gostou do conteúdo? Compartilhe com outros engenheiros de dados que ainda estão presos no modelo ETL tradicional! 🚀