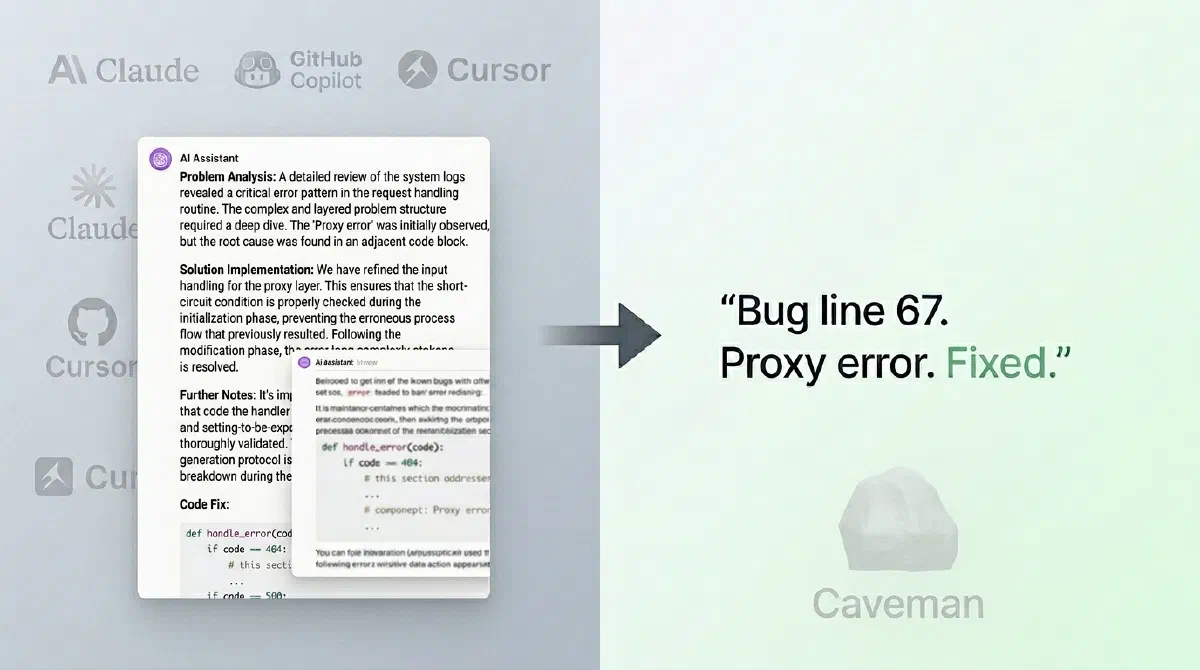
Se você já automatizou tarefas com LLMs em produção, sabe exatamente onde dói: respostas longas demais para tarefas simples.
Em muitas rotinas de engenharia, você não precisa de três parágrafos de cordialidade para descobrir se há um bug em uma função. Você precisa de:
- diagnóstico rápido;
- contexto mínimo;
- ação recomendada.
Esse é o problema que o Caveman resolve muito bem.
O que é o Caveman?
O Caveman é uma skill/plugin para agentes de IA (como Claude Code e Copilot) que força um estilo de resposta extremamente direto, com menos floreio e menos tokens.
A ideia é simples:
- cortar frases de cortesia;
- reduzir explicações não solicitadas;
- manter só a informação que realmente importa.
O resultado é um modo de comunicação “telegráfico”, mas ainda técnico.
Em vez de:
“Claro, excelente pergunta. Vamos analisar esse trecho com calma e considerar alguns pontos importantes antes de chegar à solução…”
Você recebe algo como:
“Bug em validação de nulo. Linha X. Adicionar check antes de acessar atributo.”
Menos bonito. Muito mais útil em pipeline.
Por que “persona” funciona melhor do que só pedir “seja breve”?
Um detalhe interessante da engenharia de prompt aqui: pedir “seja conciso” nem sempre funciona de forma consistente.
Modelos tendem a voltar para o comportamento padrão de “ajudar com contexto completo”. Já uma persona com regras claras (no caso, o estilo caveman) cria uma âncora comportamental mais forte.
Na prática:
- instrução vaga: comportamento oscila;
- persona definida: comportamento mais previsível.
Para quem roda fluxos repetitivos, previsibilidade vale ouro.
Como instalar
Há duas opções diferentes conforme o ambiente.
Claude Code (plugin)
|
|
Instalação via skills (multi-agente)
|
|
Se você quiser instalar a skill para um agente específico (em vez de instalar no modo padrão), use a flag -a.
Exemplos:
|
|
Regra prática: se você trabalha com mais de um agente na mesma máquina, usar -a evita confusão e deixa explícito onde a skill foi ativada.
Como usar no dia a dia
O Caveman traz níveis de intensidade, como lite, full e ultra.
Conceitualmente:
lite: reduz gordura, mantém gramática mais natural;full: modo caveman padrão;ultra: máxima compressão de resposta.
| Modo | Comando | Estilo | Melhor uso |
|---|---|---|---|
| Lite | /caveman lite |
Remove filler, mantém gramática | Trabalho técnico com legibilidade alta |
| Full | /caveman full |
Caveman padrão, frases mais curtas | Revisões e triagem diária |
| Ultra | /caveman ultra |
Compressão máxima, telegráfico | Pipelines automatizados e alto volume |
No fluxo diário, isso é excelente para alternar entre:
- modo produtividade (review, triagem, debugging);
- modo explicação (quando você realmente quer detalhe).
Antes / Depois
| Cenário | 🗣️ Claude normal | 🪨 Claude caveman |
|---|---|---|
| Re-render em React | (69 tokens) “O motivo do seu componente React estar renderizando novamente provavelmente é que você está criando uma nova referência de objeto a cada ciclo de renderização. Quando você passa um objeto inline como prop, a comparação rasa do React entende que é um objeto diferente toda vez, o que dispara um re-render. Recomendo usar useMemo para memorizar o objeto.” |
(19 tokens) “Nova referência de objeto a cada render. Prop inline = nova ref = re-render. Envolver com useMemo.” |
| Middleware de autenticação | “Claro! Fico feliz em ajudar. O problema que você está enfrentando provavelmente ocorre porque seu middleware de autenticação não está validando corretamente a expiração do token. Deixa eu analisar e sugerir uma correção.” | “Bug no middleware de auth. Checagem de expiração usa < em vez de <=. Correção:” |
Mesma correção. 75% menos palavras.
Onde ele brilha
O ganho é maior em tarefas técnicas estruturadas, por exemplo:
- sumarização de função;
- explicação de erro;
- comentários de code review;
- triagem de logs;
- passos de correção em CI/CD.
Nesses cenários, o próprio ecossistema do Caveman reporta reduções expressivas de tokens em benchmarks e exemplos práticos.
Menos tokens de saída geralmente significa:
- menor latência percebida;
- menor custo por chamada;
- melhor escaneabilidade para humanos.
Benchmarks comparativos
| Tarefa | Tokens sem Caveman | Tokens com Caveman | Redução |
|---|---|---|---|
| Explicar bug de re-render em React | 1180 | 159 | 87% |
| Corrigir expiração de token no middleware de auth | 704 | 121 | 83% |
| Configurar pool de conexões PostgreSQL | 2347 | 380 | 84% |
| Explicar git rebase vs merge | 702 | 292 | 58% |
| Refatorar callback para async/await | 387 | 301 | 22% |
| Arquitetura: microservices vs monolito | 446 | 310 | 30% |
| Revisar PR em busca de falhas de segurança | 678 | 398 | 41% |
| Build Docker multi-stage | 1042 | 290 | 72% |
| Depurar condição de corrida no PostgreSQL | 1200 | 232 | 81% |
| Implementar error boundary em React | 3454 | 456 | 87% |
| Média | 1214 | 294 | 65% |
Resumo: faixa de economia entre 22% e 87%, dependendo do tipo de prompt.
Onde você não deve usar
Nem tudo é martelo.
Evite Caveman quando comunicação, nuance e empatia são parte central da entrega:
- conteúdo para cliente final;
- documentação didática;
- tópicos sensíveis (jurídico, saúde, compliance);
- explicações para pessoas iniciantes no tema.
Nesses casos, comprimir demais pode remover contexto importante.
Exemplo de política híbrida (recomendado)
Uma estratégia madura é ativar compressão só para tipos de tarefa que realmente se beneficiam disso.
|
|
Esse padrão evita dois extremos:
- gastar token à toa em tarefas mecânicas;
- empobrecer comunicação em tarefas que exigem contexto.
Um recurso subestimado: compressão de contexto
Além da resposta curta, o projeto também explora compressão de arquivos de contexto (como instruções e memória de sessão), preservando elementos técnicos sensíveis (código, paths, comandos) enquanto comprime texto explicativo.
Isso é especialmente útil quando seu agente lê arquivos fixos em toda sessão.
Menos tokens de contexto recorrente = mais espaço para tarefa real.
Tabela comparativa do caveman-compress (input/contexto)
| Arquivo (exemplo) | Antes | Depois | Redução |
|---|---|---|---|
| claude-md-preferences.md | 706 | 285 | 59.6% |
| project-notes.md | 1145 | 535 | 53.3% |
| claude-md-project.md | 1122 | 687 | 38.8% |
| todo-list.md | 627 | 388 | 38.1% |
| mixed-with-code.md | 888 | 574 | 35.4% |
| Média | 898 | 494 | 45% |
Aqui o foco não é só saída: é reduzir também o “custo de leitura” do contexto carregado em toda sessão.
Resumo
O Caveman é uma forma simples e prática de tornar respostas de IA mais curtas sem perder o núcleo técnico. Em tarefas repetitivas e estruturadas, os dados do próprio projeto mostram reduções relevantes de tokens, com impacto direto em velocidade de leitura, latência e custo.
A principal lição é objetiva: comportamento padrão de modelo não é necessariamente o melhor comportamento para produção. Ao ajustar o estilo de resposta com uma skill específica, você aproxima o agente do que realmente importa no dia a dia de engenharia: eficiência operacional, previsibilidade e decisão rápida.